Beim Import der Daten in eine relationale Datenbank wurde jede Wortstrecke des GWb als eigenständiges TEI/XML-Dokument behandelt. Unter Berücksichtigung des von der TEI vorgesehenen Schemas zur Codierung von Wörterbüchern wurden die Daten zunächst validiert, und anschließend wurde intern eine hierarchische Repräsentation des Dokumentes aufgebaut, die im Wesentlichen die Top-Down-Gliederung der XML-Markierungen widerspiegelt. Ausgehend von einem Wurzelknoten, der als Ausgangspunkt für das ganze Dokument dient, folgen auf einer nächsten Ebene die einzelnen Wortartikel (markiert als <entry>). Diese wiederum enthalten auf tiefer liegenden Ebenen die Elemente zur Beschreibung der Lemmata, der lexikografischen Interpretamente, der Belegzitate usw. Alle diese strukturierenden Elemente werden durch sogenannte Elementknoten abgebildet.

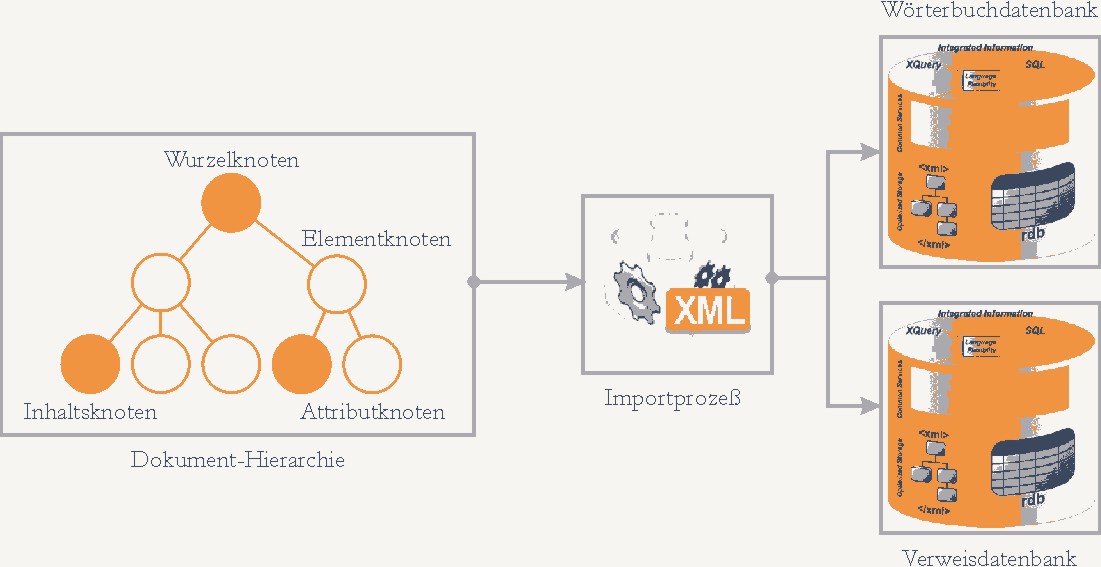
Die eigentlichen Textteile des Wörterbuchs, etwa die Zeichenfolge eines Stichwortes oder der Wortlaut eines Belegs, werden durch Inhaltsknoten beschrieben, die den zugehörigen Elementknoten untergeordnet sind. Präzisierende Einheiten wie z.B. der Typ eines Stichwortes (Hauptstichwort, Variante, Nebenstichwort) werden durch Attribute im XML-Dokument angegeben (<form type="variant">). Die Attribute werden in der hierarchischen Baumdarstellung wiederum durch sogenannte Attributknoten wiedergegeben, die ebenfalls dem zugehörigen Elementknoten zugewiesen sind. Am Ende dieses Vorverarbeitungsschrittes liegt also das gesamte XML-Dokument in einer hierarchisch eindeutigen Beschreibung vor, die mit Hilfe von definierten Zugriffsmechanismen systematisch abgesucht werden kann. Beispielsweise können so auf einfache Weise zu einem Elementknoten alle seine Nachfolger auf der nächst tieferen Ebene abgerufen werden. Auf die oberste Ebene angewandt etwa liefert dieser Zugriff alle Wörterbuchartikel der gerade bearbeiteten Wortstrecke. Ein Schritt über die nächst tiefere Ebene auf die darunter liegenden Inhaltsknoten liefert dann alle Stichwörter.